Google Analyticsと自作アクセス解析ツールのアクセス数の差
アクセス解析に関しては、私は非常に敏感です。初めて公開したWebサービスがアクセス解析ツールだったこともあり、現在でもGoogle Analytics(以下GA4)と自作のアクセス解析ツールを併用して、アクセスログを収集しています。
しかし、GA4と自作ツールで1日のアクセス数を比較すると、倍近い差が出ることがあります。特に、自作ツールの方が多くカウントされるのです。検索エンジンなどの自動収集プログラム(以下、ボット)からのアクセスは特定のキーワードをもとに除外していますが、それでもこの差が生じます。一体なぜなのでしょうか?
ブラウザを装ったアクセス
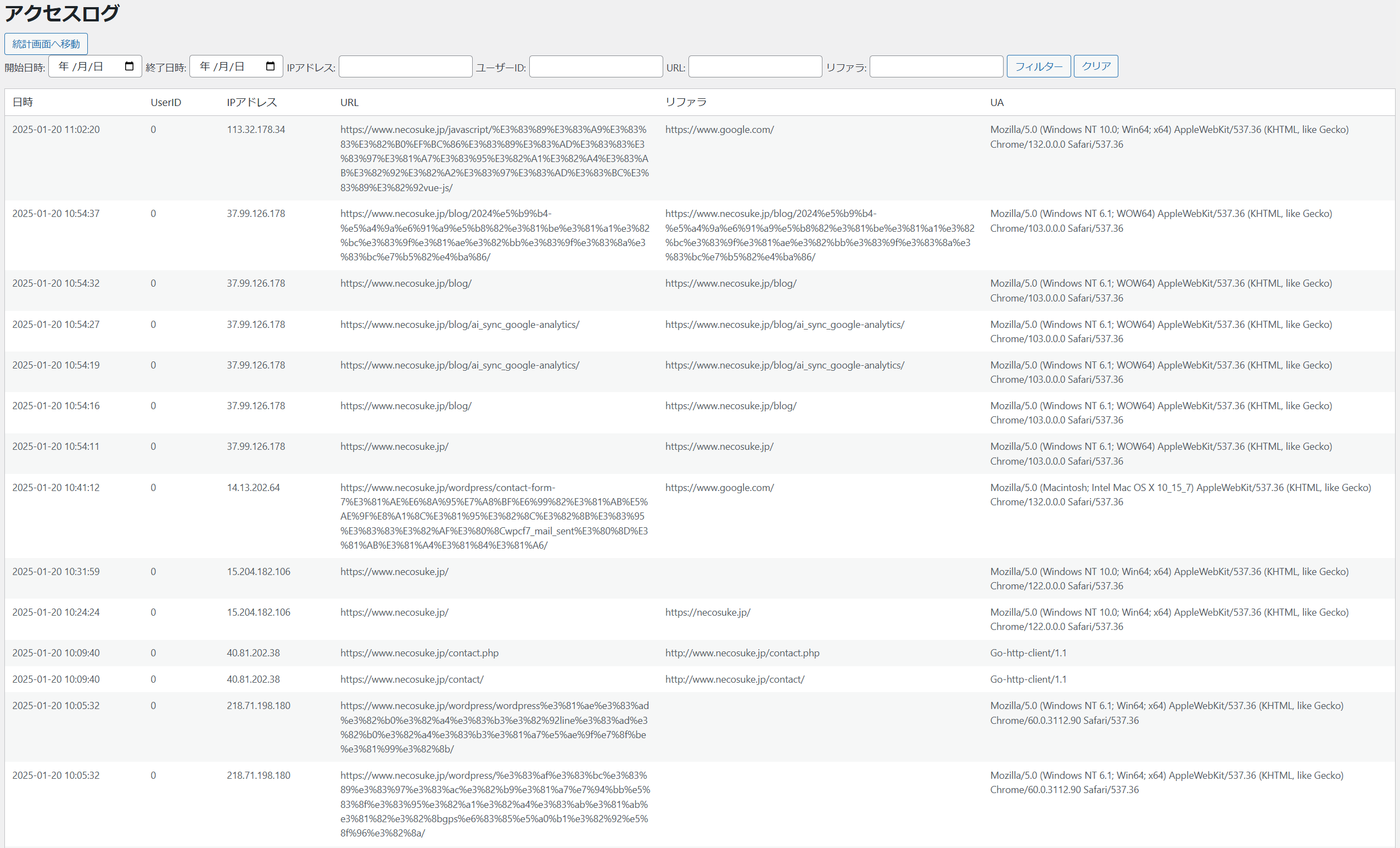
アクセスログを詳しく見ると、「MacのSafariからのアクセス」といった情報が付いているものの、同じ時刻に20ページ以上を一度に閲覧するログが残っていたり、test、demo、backup、www、main、old、old-siteなど、存在しないページへの大量のアクセスがあります。
これらのアクセスは何の目的で行われているのでしょうか?一見すると普通のブラウザからのアクセスのようですが、実際にはページ間のリンクを辿っていないため、すぐに不自然だと分かります。しかし、私の技術ではこれらを自動的に「ボットのアクセス」と判定することは困難です。おそらくGA4では独自の仕組みで偽装したボットのアクセスを除外しているのでしょう。
ボットのアクセスがもたらす問題
ボットのアクセスは、マーケティングデータとしては全く役に立たないだけでなく、データ分析を複雑にしてしまいます。今後AIが進化すれば、Googleでもボットと人間のアクセスを見分けるのが難しくなるかもしれません。
そもそも、ボットのアクセスの目的は何なのでしょうか?なぜ偽装してアクセスしてくるのでしょうか?データ収集、セキュリティ検査、広告詐欺、競合調査などが考えられますが、身分を隠しているのはなぜなのでしょうか?不正な目的があるのかもしれません。
ボットのアクセスを防ぐには
ボットによる不正なアクセスを防ぐ方法の一つに、GoogleのreCAPTCHAのようなCAPTCHAがあります。これは、自動化されたアクセスをブロックする効果が期待できます。CAPTCHAは「あなたは人間ですか?」といった内容のメッセージでユーザーを不快にさせることもありますが、実際にはボットと人間をかなり正確に見分けることができます。今後、フォームだけでなく全ページにCAPTCHAを導入することが必要になるかもしれません。
皆さんのWebサイトでも、気付いていないだけで同様のボットアクセスが問題となっているかもしれません。もし心配な点があれば、一度アクセス解析を見直してみてはいかがでしょうか?